8. Funktioner
När ett program börjar bli för stort kan det vara bra att dela upp det i mindre delar. Ett av verktygen för att göra detta kallas funktionsindelning, man delar upp programmet i funktioner. En funktion är vad det heter, det vill säga något som utför en funktion av något slag.
Vi har faktiskt redan skrivit en funktion, men utan att veta något speciellt om funktioner. Funktionen i fråga heter main(), och vi har skapat en sådan till varje program vi skrivit hittills. Varför behövs nu main()? Hemligheten ligger förborgad i operativsystemets sätt att arbeta.
Om man nu inte vet någonting om operativsystem, kan vi i alla fall nämna att en av dess uppgifter är att möjliggöra programkörning. Datorns huvuduppgift är ju att köra program, men hur sker det egentligen? Programmen finns skrivna på till exempel en hårddisk, och så länge de bara finns där gör de ingen nytta.
Hjärtat i en dator är dess centrala bearbetningsdel, Central Processing Unit, CPU, i dagligt tal kallad mikroprocessorn. Mikroprocessorn kan i stort sett bara utföra beräkningar och flytta data mellan olika delar av minnet. Naturligtvis kan den även läsa de instruktioner som säger vad den ska göra, och därför kan den läsa dessa steg för steg från datorns primärminne, RAM, det vill säga de IC-kretsar som utgör datorns minne. Dessa omnämndes i kapitel 4.
Mikroprocessorn kan inte läsa från disken. Den kan bara läsa från primärminnet. Det är en av operativsystemets uppgifter att lösa detta problem. Operativsystemet läser in vårt program i primärminnet, och ser till att mikroprocessorn börjar bearbeta dess instruktioner. Det sistnämnda sker genom att operativsystemet anropar main() i vårt program. När man anropar en funktion utför mikroprocessorn de programsteg som finns i funktionen.
Man anropar en funktion genom att skriva dess namn. I ett program kan man skriva funktionens namn i källkoden, så anropas funktionen vid den punkt i programmet där funktionens namn står.
När man skriver ett kommando vid DOS-prompten, läses detta kommando av DOS kommandotolk, den funktion i DOS som tolkar de kommandon man skriver. När denna ser att det inte är ett internt doskommando, det vill säga det finns inte i primärminnet, letar kommandotolken på hårddisken. Först letar den i den aktuella katalogen. (Man kan byta aktuell katalog med hjälp av kommandot cd.) Sedan letar den i de kataloger som angivits i miljövariabeln PATH. Om den hittar en fil med samma namn som kommandot, och med ett filnamnstillägg som heter exe eller com, så läser den in programmet till primärminnet och ser till så att mikroprocessorn börjar bearbeta programstegen där programmet lagts.
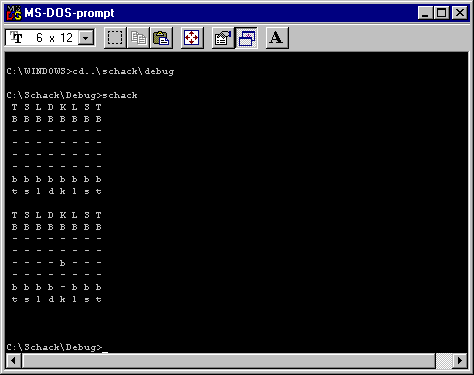
Så här kan vi till exempel starta ett av våra tidigare program. Starta MS-DOS-prompt. Navigera, det vill säga använd kommandot 'cd' till att leta upp den katalog där programfilen ligger. Tänk på att programfilen inte ligger direkt i projektkatalogen. Här nedan har jag startat programfilen Schack.exe i debugkatalogen till projektet Schack:
|
Definition: En funktion är ett isolerat program,
avsett att anropas av andra funktioner eller program. En funktion har ett
namn, vilket används vid anrop. Funktionens namn avslutas med ett
parentespar. När man anropar en funktion utför mikroprocessorn de
programsteg som finns i funktionen.
|
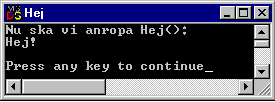
Nu är det dags att testa att skriva en funktion. Låt oss deklarera en funktion som heter 'Hej()':
void Hej()
{
cout << "Hej!\n"
}
Som synes ser deklarationen ut precis som när vi deklarerar main(). Att deklarera en funktion innebär alltså att man skriver den. Man skriver först funktionens huvud, och sedan dess kropp. Vi ska titta närmare på huvudet i kommande avsnitt. Kroppen består av ett kodavsnitt, det vill säga först en inledande klammer, sedan en eller flera programsatser och eventuella variabeldeklarationer, och till sist en avslutande klammer.
Vårt program måste fortfarande innehålla en funktion main(), så att operativsystemet kan starta det. Låt oss deklarera main() i samma fil. Vi ska anropa funktionen Hej() från main(), så main måste stå efter Hej(). Vi ska titta mer på ordningen senare. Så här ser hela programmet ut:
#include <iostream.h>
void Hej()
{
cout << "Hej!\n";
}
void main()
{
cout << "Nu ska vi anropa Hej():\n";
// Anropa Hej():
Hej();
cout << '\n';
}
Så här blir utskriften:
Övningsuppgift 8.1.1:
Övningsuppgift 8.1.2:
Övningsuppgift 8.1.3:
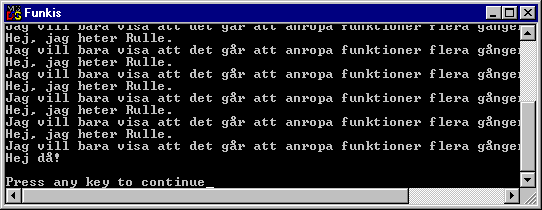
Funktioner har även den egenskapen att de isolerar sina variabler från de övriga funktionerna. En variabel som är deklarerad i en funktion är alltså inte tillgänglig i andra funktioner. Låt oss skapa ett program med en lokal variabel:
#include <iostream.h>
void Funk()
{
iTal++;
}
void main()
{
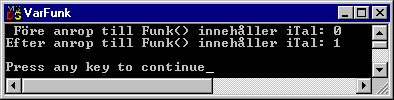
// Lokal variabel i main():
int iTal = 0;
cout << " Före anrop till Funk() innehåller iTal: " << iTal << '\n';
// Anropa Funk():
Funk();
cout << "Efter anrop till Funk() innehåller iTal: " << iTal << "\n\n";
}
Här har vi en variabel som är deklarerad i main(). Försöker vi kompilera detta exempel får vi kompileringsfel på programinstruktionen '
iTal++' i Funk().Övningsuppgift 8.2.1:
Övningsuppgift 8.2.2:
Finns det då ingen möjlighet för olika funktioner att ha gemensamma variabler? Jo, det finns ett sätt. En variabel kan deklareras globalt. En global variabel är tillgänglig, känd, i alla funktioner som kompileras vid en kompilering. Variabeln bör deklareras i början, eftersom den naturligtvis inte är tillgänglig innan den är deklarerad.
Här är det på sin plats med en kort diskussion om den ordning i vilken vi deklarerar variabler och funktioner. Kompilatorn läser texten i källkoden i den ordning den står, och kan inte acceptera att vi anropar en funktion eller använder en variabel som ännu inte är deklarerad, det vill säga som den inte hunnit läsa än. Vi kommer senare att se metoder att i viss mån kringgå detta. Vanligen deklareras alla globala variabler i början av källkoden, medan de flesta lokala variabler står i början av respektive funktion.
I C++ talar man om sammanhang, scope, och det vi nu diskuterat är globalt sammanhang respektive lokalt sammanhang. På engelska heter det global scope respektive local scope.
Övningsuppgift 8.2.3:
Övningsuppgift 8.2.4:
Alla funktioner har ett namn, och i namnet ingår parenteserna, men varför står det void framför de funktioner vi hittills skrivit? Jämför man en variabeldeklaration med en funktionsdeklaration kanske man ser ett mönster: först står datatyp och sedan namn. Så kan man i alla fall tolka det om 'void' är en datatyp, och void är faktiskt en speciell sorts datatyp. Void betyder 'utan värde', och används för att tala om att funktionen inte svarar med något värde. Vi ska strax titta på hur en funktion kan svara med ett värde. Faktum är att det kunde stått en vanlig datatyp framför, till exempel int:
int Funk()
{
...
}
Nu har vi en funktion som har ett värde. Detta innebär att man kan göra tilldelningar, jämförande operationer etcetera med funktionen:
a = Funk();
if(Funk() > 3)
{
...
}
Nu är det lättare att se likheten mellan en variabeldeklaration och en funktionsdeklaration:
int iTal;
int Funk()
{
}
Det är alltså parenteserna som avgör om vi deklarerar en variabel eller en funktion. Vi skulle alltså till och med kunna deklarera en variabel med samma namn som en funktion. Det är dock inte att rekommendera. Nedanstående exempel är ju rätt så förvirrande:
int main()
{
int main;
main = 5;
cout << "main = " << main << "\n\n";
}
Varför skulle då en funktion ha en datatyp? Detta ska vi ta och titta på i nästa avsnitt.
4. Return: instruktion, typ och värde.
En funktion har ett kodavsnitt. Om funktionen inte har något returvärde kommer den att återlämna kontrollen till den anropande funktionen när den utfört alla programsatser fram till slutklammern:
void Funk()
{
programrader
...
} // Här återlämnas kontrollen till den anropande // funktionen.
Man kan också avbryta bearbetningen med programinstruktionen return:
void Funk()
{
programrader
...
if(villkor)
{
eventuella programrader
...
return; // Här återlämnas kontrollen till den
} // anropande funktionen om villkor är
// uppfyllt.
...
} // Här återlämnas kontrollen till den anropande // funktionen om villkor inte är uppfyllt.
Är funktionen av annan typ än void, så måste den lämna ett returvärde. Den sista satsen före slutklammern måste alltså vara 'return'. För att funktionen ska lämna över ett returvärde ska detta stå efter ordet 'return':
int Funk() // Funktionen Funk är av typen int.
{
programrader
...
return 0; // Returnerar värdet noll.
}
Man kan naturligtvis även använda en variabels värde att svara med.
int Funk()
{
int iSvar;
...
return iSvar; // Svarar med värdet i variabeln iSvar.
}
Hur tar man då emot returvärdet? Man betraktar själva funktionsanropet som ett uttryck som har samma typ som funktionens. Därigenom kan man t.ex. använda en tilldelningsoperator för att ta emot värdet. Man kan testa på funktionsanropet direkt med t.ex. en if-sats etc.
iAntal = raekna(); // Returvärdet från funktionen // raekna hamnar i variabeln // iAntal.
if(raekna() == 5) // if-satsens kodavsnitt utförs
{ // om funktionen raekna returnerar
... // värdet 5.
}
if((iAntal = raekna()) == 5)
{ // Returvärdet från raekna läggs i
... // iAntal, och om det är 5 kommer
} // if-satsens kodavsnitt att // utföras.
if(!strcmp(str1, str2)) // strcmp() jämför två textsträngar
{ // och returnerar 0 om de är lika.
... // if-satsens kodavsnitt kommer att
} // utföras om str1 innehåller samma text som str2.
Övningsuppgift 8.4.1:
Skriver man flera funktioner i samma källkod kan en eller flera variabler vara globalt kända genom att de deklarerats före funktionerna. I övrigt gäller att en funktion endast känner sina egna variabler, de som är deklarerade i funktionen.
Hur kan man då föra över värden från en anropande funktion till en anropad funktion, utan att använda globala variabler?
En funktion kan bara ha ett enda returvärde (eller inget alls), men man kan förse funktionen med flera olika värden att arbeta med. Dessa kallas funktionens parametrar, eller argument. Man deklarerar argumenten inom de parenteser som alltid följer funktionens namn, i viss ordning och åtskilda av kommatecken. Det går sedan att ange värden inom parenteserna när man anropar funktionen. Dessa värden måste då stå i motsvarande ordning.
När man skriver funktionen deklarerar man argumenten så som de kommer att heta inom funktionen (det behöver inte vara samma namn som den anropande funktionen använder, om den lämnar över värden via variabler):
float Multi(float fTal1, float fTal2)
{
float fSvar;
fSvar = (float)(fTal1 * fTal2);
return fSvar;
}
Den anropande funktionen kan t.ex. göra följande:
...
float fFaktor1, fFaktor2, fProdukt;
...
fProdukt = Multi(fFaktor1, fFaktor2);
Observera att vi passerar värden från den anropande funktionens variabler till den anropade funktionens argument. Vi kommer att titta på ett annat sätt under avsnittet ‘Anrop med pekare’.
Nu har vi förklarat alla delar i programmet Hello, utom en, nämligen den första raden:
#include <iostream.h>. Alla reserverade ord som börjar med ett nummertecken, '#', eller brädgård som det populärt kallas, är så kallade kompileringsdirektiv. Det är kommandon till kompilatorn, och de blir i sig inte översatta till maskinkod. Kompileringsdirektivet #include instruerar kompilatorn att öppna en annan fil och läsa hela den filen på den plats där #includesatsen står.Filnamnet anges som en textsträng, vilket normalt brukar vara en text innesluten mellan dubbla citattecken (dubbelfnuttar, kaninöron etcetera brukar man populärt kalla dem). Om vi till exempel vill att kompilatorn ska läsa en fil vi kallar MinFil.h som ligger i katalogen Headers på hårddisken C: skulle det kunna åstadkommas med följande includesats:
#include "c:\headers\minfil.h"
Observera att en includesats inte är en programsats och därför inte avslutas med semikolon.
Om filen finns i samma katalog som källkoden, så behöver man inte ange sökvägen:
#include "minfil.h"
Om filen levererats med utvecklingspaketet, det vill säga i vårt fall Developer Studio och Visual C++, finns den i en speciell katalog, antingen i d:\msdev\includes\ eller d:\msdev\mfc\includes\. För att man ska slippa att skriva hela sökvägen till dessa kataloger, så finns de angivna under Directories-fliken i Options-dialogrutan. Dessa inställningar görs automatiskt när man installerar Developer Studio och Visual C++. Vill du se dem, så hittar du dialogen under [Tools - Options]. Man anger att man vill använda denna automatik genom att byta ut de dubbla citattecknen mot '<' och '>':
#include <iostream.h>
Observera att vi här talar om filnamn, och bakåt kompatibilitet mot DOS gör att stora och små bokstäver inte gör skillnad. Därför är MinFil.h, minfil.h och MINFIL.H samma filnamn.
Detta oberoende av var filerna finns utgör en viktig fördel. Om man installerar C++ i någon annan katalog behöver man alltså inte ändra i sina källkoder. Samma sak gäller filer som ligger i projektkatalogen, de är inte beroende av var projektet finns.
Övningsuppgift 8.5.1:
När man skickar argument till en funktion kommer bara värden att skickas över. Detta kallas för värdeanrop. Funktionen som anropas har egna lokala variabler att manipulera. Det betyder att funktionen inte kan ändra värdet på de variabler vars värden man skickar. Detta visar sig genom att den anropande funktionen inte kan se ändringen. Vi kan se detta i nedanstående exempel:
#include <iostream.h>
void PlusTre(int iTal)
{
iTal += 3;
}
void main()
{
int iTal = 4;
cout << " Före anrop innehåller iTal: " << iTal << '\n';
PlusTre(iTal);
cout << "Efter anrop innehåller iTal: " << iTal << '\n';
cout << '\n';
}
Så här ser det ut när vi kör ovanstående program:
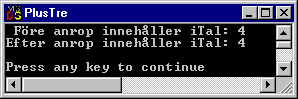
Som vi vet från tidigare är iTal, i main(), inte är samma variabel som iTal, i PlusTre()! Vi kommer att titta mer på detta i avsnittet ‘Räckvidd’, men nu ska vi se hur man kan lösa detta genom att använda pekare.
Man kan i stället skicka med en adress som argument. Om den pekar på en variabel som den anropande funktionen känner till, kan den anropade funktionen ändra variabelns värde:
#include <iostream.h>
void PlusTre(int *ipTal)
{
*ipTal += 3;
}
void main()
{
int iTal = 4;
cout << " Före anrop innehåller iTal: " << iTal << '\n';
PlusTre(&iTal);
cout << "Efter anrop innehåller iTal: " << iTal << '\n';
cout << '\n';
}
Observera att anropet i main lämnar adressen till iTal som argument. Alternativt kunde det vara en pekare:
int *p;
p = &iTal;
PlusTre(p);
Funktionen PlusTre() deklarerar sedan en pekare i sin argumentlista, det vill säga mellan parenteserna. Den pekaren kommer att innehålla adressen till variabeln iTal i main(). När vi manipulerar via pekaren är det alltså iTal i main() vi manipulerar. Därför blir nu utskriften:
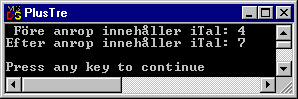
Övningsuppgift 8.6.1:
Övningsuppgift 8.6.2:
Övningsuppgift 8.6.3:
Som vi redan sett kan man deklarera variabler på olika ställen. Det som är intressant är att de därigenom har olika räckvidd. Skriver man en källkod med flera funktioner, alternativt lägger funktioner i headerfiler, kan man deklarera en variabel i början av källkoden, eller i en funktion.
En variabel som deklarerats i början av källkoden (utanför första funktionen) är känd av alla funktioner i källkoden. Den kallar vi ‘globalt deklarerad’.
En variabel som deklarerats inuti en funktion är känd bara i den funktionen. Den kallar vi ‘lokalt deklarerad’. Dess räckvidd (scope) är begränsad.
Om dom har samma namn då?
Två variabler som deklarerats lokalt med samma namn i två olika funktioner är i praktiken två olika variabler, d.v.s. de lagras på två olika ställen i minnet.
En variabel som deklarerats globalt är känd i alla funktioner, men om någon funktion har en lokalt deklarerad variabel med samma namn är den globalt deklarerade variabeln inte längre känd. Variabelnamnet får automatiskt en lokal betydelse.
#include <iostream.h>
int a; // Känd av alla funktioner.
int b; // Känd av main()och funk_b()
// men ej av funk_a().
void Funk_a()
{
int b; // Lokal variabel, hindrar referens
a = 1; // till globala b.
b = 2;
}
void Funk_b()
{
a = 3; // Endast globala variabler.
b = 4;
}
void main()
{
a = 5;
b = 6;
cout << "Variabeln a = " << a << " och b = " << b << '\n';
Funk_b();
cout << "Variabeln a = " << a << " och b = " << b << '\n';
Funk_a();
cout << "Variabeln a = " << a << " och b = " << b << '\n';
}
Ovanstående program resulterar naturligtvis i följande utskrift:
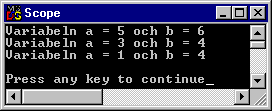
Övningsuppgift 8.7.1:
Övningsuppgift 8.7.2:
Övningsuppgift 8.7.3:
Övningsuppgift 8.7.4:
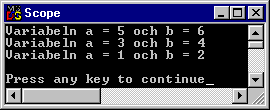
Om man nu deklarerar en variabel lokalt, med samma namn som en global variabel, blir det två separata variabler med samma namn, en global och en lokal. Vill man ändå att det ska vara samma variabel (d.v.s. lagras på samma fysiska plats i datorns minne) så kan man i den lokala deklarationen använda nyckelordet extern.
En annan lagringsklass är auto. Denna har omvänd funktion, d.v.s. man isolerar en lokalt deklarerad variabel från en eventuellt globalt deklarerad variabel med samma namn. Nu tänker du: "Men så var det ju från början!" Helt riktigt. Om man inte anger lagringsklass antas automatiskt lagringsklass ‘auto’.
Förutom ‘extern’ och ‘auto’ finns ytterligare två lagringsklasser: static respektive register.
Varje gång en funktion anropas kommer den att deklarera sina interna variabler, varefter de initieras på nytt, eller får skräpvärden om de inte initieras. Detta innebär att en funktion inte ‘kommer ihåg’ vad den sysslade med mellan de olika anropen. Alla lokalt deklarerade variabler är av temporär art. De kan dock göras statiska, det vill säga sådana att de behåller sina värden mellan anropen, genom att man använder nyckelordet ‘static’ vid deklarationen. Därigenom deklareras och initieras en variabel bara första gången funktionen anropas.
Den sista lagringsklassen är ‘register’. Den betyder att man vill att datorn lagrar data direkt i något av processorns register, några mycket få och mycket upptagna ‘minnen’ inuti mikroprocessorn. Om data lagras där sker bearbetning mycket snabbare än annars. Det är dock inte säkert att det finns ledigt registerutrymme. Nu har nyckelordet 'register' inte längre någon praktisk betydelse. Tidigare uppfattade kompilatorn det som en rekommendation, och följde den endast om det fanns något ledigt register. Vår version av kompilatorn kommer i alla fall att optimera programmet, och rekommenderar därigenom sig själv där så är lämpligt.
Vi ska ta och testa att göra en statisk variabel. Låt oss först deklarera en funktion som räknar åt oss:
int Counter()
{
int iTal = 0;
return ++iTal;
}
Tanken är att funktionen Counter() ska returnera värdet 1 vid första anropet, 2 vid andra och så vidare. Observera syntaxen här: ++iTal betyder att iTal ska ökas med ett innan dess värde används, i detta fall som returvärde.
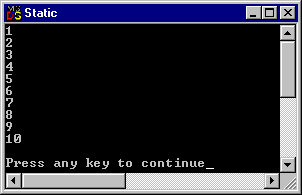
Vi kan testa detta genom att skapa en programslinga i main() som anropar Counter() tio gånger:
for(int iGgr = 0; iGgr < 10; iGgr++)
{
cout << Counter() << '\n';
}
Resultatet blir naturligtvis inte det vi vill, eftersom Counter() initierar iTal till noll vid varje anrop:
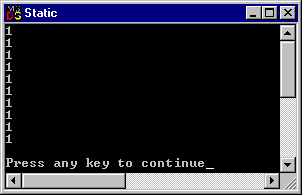
Övningsuppgift 8.8.1:
API betyder Application Programming Interface. Språket C++ har egentligen inte särskilt mycket funktionalitet i sig självt. Det är dock starkt utbyggbart. Vi kommer senare att titta på hur man skapar klasser och objekt, men vi har redan sett hur man kan skapa funktioner, vilka fungerar som 'svarta lådor' som utför en uppgift bara vi skriver dess namn.
Man bör här, som i de flesta andra sammanhang, undvika att uppfinna hjulet mer än en gång. Andra har sett att C++ inte kan skriva ut text på bildskärmen, och har skapat objekten cin och cout åt oss. När man köper Visual C++ får man dessa objekt på köpet. De finns färdigkompilerade på disken i en så kallad library-fil. När vårt projekt länkas hämtas de funktioner vi behöver till objekten cin och cout från denna fil.
När vi kompilerar våra program måste dock kompilatorn känna till objekten cin och cout. Därför finns så kallade fördeklarationer i en fil som heter iostream.h. En fördeklaration av en funktion är helt enkelt en avskrift av funktionsuvudet, vilket sedan avslutas med ett semikolon i stället för kodavsnittet. Objekt kan också fördeklareras på liknande sätt, men vi väntar med objekt till senare.
Hela detta paket kallas API.
Vi har massor av funktioner med Visual C++ API. I hjälpen står beskrivet hur man använder funktionen, och vilken headerfil man måste använda för att få tillgång till funktionen. I vissa fall måste man ändra projektinställningarna för att komma åt själva objektkoden, men det hoppar vi över här. Vi ska i stället titta litet på diverse strängfunktioner.
Det finns en fil som heter string.h. Den ligger i vårt fall i katalogen d:\msdev\include\. Man kan få tillgång till de funktioner som beskrivs däri genom att skriva:
#include <string.h>
Om man öppnar filen från Developer Studio kan man läsa vad den innehåller. Man kan även ändra i den, men det ska vi definitivt inte göra. Däremot kan det vara intressant att se vilka funktioner vi får tillgång till. Filen är indelad i olika avsnitt. Det sista avsnittet heter 'Function prototypes', och det är där vi ser vilka funktioner som finns. Allt som står i tidigare avsnitt är diverse deklarationer som funktionerna är beroende av. Funktionernas kodavsnitt, kroppar, står inte här, bara dess huvuden, headers. Det är därifrån man har fått begreppet header files, och det är därför de har filnamnstillägget '.h'.
Låt oss betrakta ett par funktioner, strcat(), strcmp() och strlen(). Vi kan börja med strlen(). Det lättaste sättet att få mer information om en funktion är att sätta markören i funktionens namn och sedan trycka på F1.
I hjälpen står det att strelen() ska ha en const char* som argument. Det betyder att man kan ange adressen till en text, en charlista. Om man skriver en text mellan dubbla citattecken kommer även det att uppfattas som en const char*. En pekare kan också användas, och det är ju det som char* betyder.
Det står också att strlen() returnerar ett heltal, vilket anger längden på den sträng som angivits via argumentet. Vi kan alltså få reda på längden på olika texter genom att använda strlen().
Övningsuppgift 8.9.1:
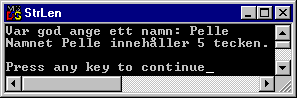
Övningsuppgift 8.9.2:
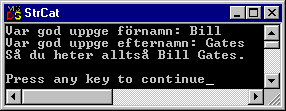
I nästa uppgift behöver vi leta i hjälpen för att se dels hur man skapar slumptal, dels hur man gör en formaterad utskrift.
Leta efter en slumptalsfunktion i hjälpen. Försök att skriva 'random' i sökfönstret, men se upp, ordet är förkortat, så att du får träff innan du skrivit färdigt.
Man kan även använda sökning i hjälpen på ett annat sätt. Observera att det finns en flik som heter query. Under den fliken har man möjlighet att ange ett eller flera sökord, vilka böcker som ska genomsökas, samt om all text eller endast titlar ska genomsökas. Vi kan använda denna sökmetod för att finna hur man kan formatera utskriften. Vi vill använda cout och styra formatet med avseende på utskriftens bredd, så lämpligen kan man prova med att skriva: cout format width, och prova att söka. Det blir inga träffar på endast titlar, men om man söker i hela texten finner man fem avsnitt. Ett av dem heter "Using Insertion Operators and Controlling Format". Där står hur man gör.
Övningsuppgift 8.9.3:
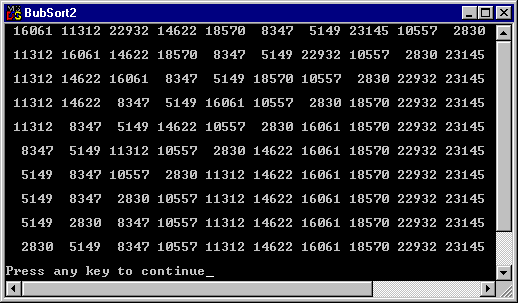
Övningsuppgift 8.9.4:
Övningsuppgift 8.9.5: