Programsats; En programsats beskriver ett bearbetningssteg i programmet. Den kan vara enkel eller komplex, d.v.s. innehålla en eller flera programinstruktioner. En programsats avslutas alltid med ett semikolon.
Programinstruktion Ett ord som talar om vad datorn ska göra.
Uttryck Programinstruktion, tilldelning, vilkorl etc. Sätter man ett semikolon efter ett uttryck blir det en programsats.
Kodavsnitt En eller flera programsatser som logiskt hör ihop, t.ex. all kod i en funktion, all kod i en while-slinga, all kod som utföres i en if-sats när villkoret är uppfyllt, respektive den kod som utföres när det inte är uppfylld etc.
Funktion() En funktion är ett program avsett att anropas från andra program. Den kan finnas i samma källkod som det anropade programmet, i en header-fil, eller en annan objektsfil. Vissa funktioner skriver du själv, vissa får du med kompilatorn. Funktionen länkas normalt in i din exe-fil.
Funktionsheader Beskriver returvärdets datatyp, funktionens namn samt förväntade parametrar (inom parantesen).
Syntax Sammansättning av Programinstruktioner, variabler, funktioner, konstanter, operatörer, tilldelningstecken etc. till en programsats.
Deklarationer Namnger och anger datatyp för variabler, klasser.och funktioner.
Operator Matematiska symboler, t.ex. +, -, * och /.
Jämförelseoperator Jämförande matematiska symboler, t.ex >, <, ==, !=.
Operand Det operationen utförs med eller på. (Variabler, konstanter, uttryck, funktionsanrop etc.)
Villkor Jämförande operation vars logiska värde (TRUE/FALSE) anger fortsatt bearbetning. (Vanligen finns orden TRUE, FALSE samt datatypen BOOL, vilka inte ingår i C/C++, speciellt deklarerade i en headerfil som medföljer kompilatorn. Vi får t.ex. automatiskt tillgång till dessa när vi använder MFC.)
Nyckelord Ord som fungerar som instruktioner till kompilator och länkare, se ‘reserverade ord’.
Kompileringsdirektiv Kommandon till kompilator och länkare som inte står i en programsats. Ska börja med ett #-tecken, t.ex. som i ‘#include’.
Klamrar {} Anger början och slutet på ett kodavsnitt, t.ex i en funktion eller i en if-sats. Jämför med ”Begin” och ”End” om du är insatt i Pascalprogrammering.
main() Huvudfunktionen i ditt program. Exekvering börjar alltid med första programsatsen i funktionen main().
return En programinstruktion som stoppar en funktion och överlämnar ett värde till det anropade programmet.
void Anger att en funktion inte lämnar något returvärde.
Variabel En namngiven lagringsplats i datorns minne där du kan manipulera innehållet.
Konstant Ett värde inskrivet i programmet, t.ex. 5, ”Ange namn: ” eller ‘A’.
Namngiven konstant En konstant som genom kompileringsdirektivet #define givits ett namn. Det handlar bara om utbyte av text.
Datatyp Anger vilken typ av data en variabel eller funktion kan innehålla eller returnerar.
Egendefinierad typ När vi
skapar nya typer som sedan kan användas precis som de grundläggande typerna.
Vanligen strukturer, unioner och klasser, men även omdefinieringar avsedda att
ge oss tydligare syntax, t.ex.
‘typedef unsigned int UINT’;
Struktur (struct) En gruppering av namngivna variabler.
Union (union) En gruppering av omdefiniering till samma minnesutrymme att hålla olika namngivna variabler vid olika tillfällen.
Klass (class) En gruppering av namngivna variabler och funktioner avsedda att användas som mall när man definierar objekt. Se OOP, Objekt-Orienterad Programmering.
Vi kommer att gå närmre in på de olika definitionerna allteftersom de dyker upp i de olika avsnitt och kapitel som följer.
Glöm aldrig att du redan har alla böcker! De följer med Developer Studio, och finns alltid tillgängliga på din bildskärm.
Eftersom vi nu lär oss C/C++ vill jag varmt rekommendera att du alltid jämför kursmaterielet med böckerna ‘C Language Reference’, ‘C++ Language Refernce’ samt ‘Language Quick Reference’.
Klicka på fliken ‘InfoView’ i det vänstra fönstret. Klicka sedan på ‘+’ framför den bok du vill öppna. Observera att flera böcker ligger i en, som i en trädstruktur. Här finner du böckerna:
När C/C++ kompilatorn reserverar utrymme för data behöver den veta två saker:
· Hur mycket utrymme krävs för varje variabel?
· Hur ska innehållet i datorns minne kodas/tolkas?
Tänk på att:
· En byte kan innehålla 256 olika kombinationer av 1-or och 0-r (256 olika värden).
· Ett word (två bytes) kan innehålla 65536 olika värden.
· Vill man ha negativa tal måste man använda en bit som tecken, då kan en byte respektive ett word bara innehålla hälften så stora tal.
· Vill man ha flyttal reserverar man ett antal bits till att tala om var kommatecknet ska finnas (eller hur många nollor det ska stå före/efter talet, s.k. mantissa).
· I en textsträng använder man en byte per bokstav.
· Det förekommer skillnader mellan olika datortyper.
Nyckelord Bytes Typ Innehåll
unsigned short 1 heltal 0 - 255
short 1 heltal -127 - +127
unsigned int 2 heltal 0 - 65535
int 2 heltal -32767 - +32767
long 4 heltal 0 - 4294967296
float 4 flyttal 3.4E-38 - 3.4E38 (7 siffrors precision)
double 8 flyttal 1.7E-308 - 3.7E308
(15 siffrors precision)
char 1 tecken bokstäver, siffror,
special/styr-tecken.
Deklarera variabler genom att först skriva datatypen och sedan variabelns namn. Man kan sedan lägga till ett likhetstecken och ett värde, för att ge variabeln ett startvärde. Det går att räkna upp flera variabler, åtskilda med kommatecken, för att ge flera variabler samma datatyp. Avsluta med semikolon.
int iAntal;
char cBokstav = ‘C’;
float fLangd, fBredd, fHojd;
short int siTal
= 5;
long lTal =
7896541235;
int iTal1 = 0,
iTal2 = 2;
? Data types - ...Prog ref... ![]() , data types - ...Quick Ref...Ranges.
, data types - ...Quick Ref...Ranges.
Låt oss definiera strukturer i syfte att kunna tillgodogöra oss de exempel som föregår kapitel 7, där vi kommer att titta närmare på dem.
En struktur är ett antal namngivna variabler under ett samlingsnamn avsedda att ligga konsekutivt (i rad efter varandra) i minnet.
Data refereras under samlingsnamnet i kombination med respektive variabelnamn. Samlingsnamnet innehåller nyckelordet ‘struct’, vilket även används vid definitionen. Låt oss kalla samlingsnamnet ‘strukturnamn’.
Först definieras strukturnamnet, och därefter de variabelnamn som ska associeras med strukturen, inklusive datatyp. Efter denna deklaration har man endast deklarerat en mall för datalagring, inga egentliga variabler, trots att deklarationerna av variabelnamnen har exakt samma syntax som vanliga variabeldeklarationer.
Därefter är det tillåtet att när som helst där man normalt kan deklarera variabler deklarera variabler enligt strukturen (strukturvariabler).
struct <strukturnamn>
{
<typ> <variabelnamn>;
...
}[<strukturvariabel>] [,<strukturvariabel>]...;
Observera att man kan deklarera strukturvariabler direkt när man deklarerar strukturen (ex. ovan). Därför är det nödvändigt att avsluta strukturdeklarationen med ett semikolon efter sista ‘}’ eller efter de strukturvariabler som deklareras. Annars kommer nästa ord att tolkas som ett försök till deklaration av nytt variablenamn. Står strukturdeklarationen sist i en headerfil kan detta generera kompileringsfel på första rad efter #include-satsen i den fil som använder headerfilen.
Syntax för senare deklaration av strukturvariabler:
struct <strukturnamn> <strukturvariabel>
[,<strukturvariabel>]...;
Observera att strukturdeklarationen bara skapar en mall, därmed är det omöjligt att initiera variablerna i själva strukturdeklarationen. De existerar inte förren man skapat själva strukturvariabeln.
Exempel, skapa en struktur:
struct konto
{
unsigned long int kontonummer;
float saldo;
}; // Glöm inte semikolonet!!!
Skapa strukturvariabler (alla får var sina egna variablar ‘kontonummer’ och ‘saldo’):
struct konto hushallskassa;
struct konto
bilkonto;
struct konto
lonekonto;
Så här kan man fylla i data:
hushallskassa.kontonummer = 4568246431;
bilkonto.kontonummer = 4568246432;
lonekonto.kontonummer = 4568246430;
Och så här kan man använda data på olika sätt:
puts(”V.G. mata in månadens löneutbetalning:”);
scanf(”%f”,&fTemp);
lonekonto.saldo += fTemp;
...
puts("Hur mycket pengar vill du överföra till
hushållskassan?”);
scanf(”%f”,&fTemp);
if(lonekonto.saldo
>= fTemp)
{
lonekonto.saldo -= fTemp;
hushallskassa.saldo += fTemp;
puts(”OK, flytta över pengarna.”);
}
else
{
puts(”Dags att gå till socialen igen!”);
}
Förutom att vi går igenom strukturer mer i kapitel 7 kommer att titta mer på dem efter hand som de används i olika sammanhang.
Man kan lägga in kommentarer i sitt program, det gör det lättare att förstå när man senare ska göra ändringar i det. Det finns två sätt att ange att en text är en kommentar (så att inte kompilatorn försöker tolka texten): Den gamla äkta C-kommentaren innesluts mellan /* och */. Den kan vara över flera rader. I Developer Studio har vi även i C-program tillgång till C++ kommentarer vilka inleds med // och varar raden ut.
I uppgiften nedan var det en rad som inte fick plats på sidan. Det är tillåtet att skriva en programsats som sträcker sig över flera rader, men den kan inte delas mitt i ett ord eller mitt i en textsträng. Om en rad är delad i en övningsuppgift är det inte nödvändigt att du delar den, i Developer Studio får du plats med långa rader. Se bara till att skriva så att det blir tydligt och överskådligt.
Övningsuppgift:
·
Skapa projektet comments.
·
Gör på samma sätt som i föregående kapitel.
·
Källkoden ska se ut så här:
#include
<stdio.h>
void main()
{
// Deklaration av
variabler.
short sAntal;
int iNr, iLager, iBest; //
Här har jag 3 st av typ int.
long
lStortTal = 4294967295;
unsigned int uiAnt1 = 11, uiAnt2 = 22,
uiAnt3 = 33;
char
cTkn = 'A'; // Vi ska testa att
räkna med char!
// Initiering av en del
variabler.
sAntal = 1;
iNr = 0;
iLager = 2421;
iBest = 1000;
cTkn += 2; // Detta borde bli ‘C’.
// Utskrifter.
printf(" sAntal =
%d\n",sAntal);
printf("lStortTal = %lu\n",lStortTal);
printf(" iNr =
%d\n",iNr);
printf(" iLager =
%d\n",iLager);
printf(" iBest =
%d\n",iBest);
/* Observera att nedanstående 2 rader egentligen är
en enda rad som inte får plats på det
här pappret! */
printf(" uiAnt1 =
%u, uiAnt2 = %u, uiAnt3 = %u\n",
uiAnt1,uiAnt2,uiAnt3);
printf(" cTkn =
%c\n",cTkn);
Kompilatorn
måste kunna känna igen vissa ord, t.ex. ”if”, ”float”, #include” etc. Andra ord
är sådana som du hittar på för att kunna referera till variabler, funktioner
etc. För att kompilatorn ska kunna veta vad du menar har man reserverat ett
antal ord.
Nedan finner
du en lista med reserverade ord i språket C. Slå själv upp de reserverade orden
i C++.
Upprepningar:
for while do
Beslut och
val:
if else switch case default
Programhopp:
break continue goto
Datatyper:
char int short long unsigned
float double struct union typedef
Lagringsklasser:
auto extern register static
Diverse:
return sizeof
? InfoView - Visual C++ Books -
Language Quick Reference - C/C++ Keywords - C/C++ Keywords.
Aritmetiska operatorer: + - * / % ++ --
Fungerar som vanliga matematiska operatorer, - kan användas till att dra ifrån ett tal från ett annat, men även som teckenvändare. % är division, där man får resten som svar i stället för kvoten (endast vid heltal).
a = a + 2; // Värdet i variabeln a ökar med två.
c = b % 3 ; // Om b t.ex. är 11 blir c = 2.
d = d * d; // d i kvadrat.
Man kan få automatisk upp/ned-räkning av en variabel före eller efter användning genom att använda ++ eller -- före respektive efter variabeln.
a++;
a--;
++a;
--a;
int a = 1;
// Följande loop skriver ut värdet på a för a = 1 till 10
while (a < 11)
{
printf("a = %d\n",a++);
}
// Följande funktion kopierar en sträng utpekad av
// pekarvariablen ”fran” till en annan sträng utpekad
// avpekarvariablen ”till”.
void kopiera(fran, till)
char *fran, *till;
{
while((*till++ = *fran++) != '\0');
}
Tilldelningsoperatorer: = += -= *= /= %=
= tilldelar variabeln till vänster värdet av uttrycket till höger.
+= adderar värdet i variabeln till höger till variabeln till vänster.
-= subtraherar på samma sätt.
*= /= %= dito för * / resp. %.
pris *= 1.2; // Höjer värdet i pris med 20%
a += 1; // Ökar variabeln a med 1
Relationsoperatorer: < > == !=
>= <=
Operatorer som jämför variabler och värden. Man kan kombinera två relationsoperatorer: Ett uttryck som innehåller relationsoperator är antingen sant eller falskt.
> större än
< mindre än
= = lika med
<= mindre än eller lika med
!= icke lika med
if(a > 5)
{
// Här står det som ska göras om a > 5
}
if(FALSE)
{
// Detta utföres aldrig, eftersom FALSE aldrig är // sant.
}
Logiska
operatorer: && ||
!
Används för att sammanställa flera relationstester till komplexa tester, när flera villkor ska vara uppfyllda, minst ett av flera villkor behöver vara uppfyllt, eller när man vill invertera svaret från ett villkor.
&& och
|| eller
! icke
if(a > 0 && a <= 5)
{
// Kod som skrivs här utförs om a är större än 0 och // samtidigt högst lika med 5. Om a är av typen int // innebär detta att a kan vara 1, 2, 3, 4 eller 5.
}
if(cBokstav == ‘A’ || cBokstav == ‘G’ || cBokstav == ‘F’)
{
// Denna kod körs om cBokstav är ”A”, ”G” eller ”F”.
}
if(!test(a,b))
{
// Om funktionen test (vilken är av typen BOOLEAN, // och därför returnerar antingen TRUE eller FALSE) // svarar FALSE ”vänder” utropstecknet på detta, och // den kod som skrivs här utföres.
}
Pekarrelaterade
operatorer: & *
Vi ska egentligen inte titta på pekare än, men för att göra denna uppräkning komplett tar vi med detta och nästa stycke redan nu.
& Adressoperatorn, en variabel inledd med ”&” ger adressen till variabeln.
* Indirekt operator, ger värdet på den minnesplats som utpekas av den variabel som följer operatorn.
// Skapa en variabel av typen int.
int iVariabel = 15;
// Skapa en pekare av typen int.
int * iPekare;
// Låt pekaren peka på variabeln.
iPekare = &iVariabel;
// Använd pekaren för att ändra värdet i variabeln.
*iPekare = 200;
Struktur
och Unionsoperatorer: . ->
Dessa operatorer används endast i samband med strukturer och unioner.
. Elementoperatorn, kombinerar ihop struktur/unionsnamn med elementnamn till ett entydigt namn.
-> Indirek operator, kombinerar en pekare mot strukturen med elementnamn till en entydig åtkomst.
// Skapa en struktur med varunummer och beskrivning och kalla // den sVara.
struct varubeskrivning
{
int iVaruNummer;
char cBenamning[25];
} sVara;
// Lägg ett värde i iVaruNummer.
sVara.iVaruNummer = 10032;
// Skapa en pekare mot strukturen.
struct varubeskrivning * sPekare = &sVara;
// Lägg ett annat värde i iVaruNummer.
sPekare->iVaruNummer = 10055;
Diverse
operatorer: ?: sizeof (typ)
?: Villkorsoperatorn, testar och ger ett värde av två beroende av testresultatet.
sizeof Ger storleken av efterföljande variabel eller typ.
(typ) Styroperator, konverterar typ från efterföljande variabel.
// Villkorsoperatorn:
// <Svaret> = <Testuttryck>?<Uttryck SANT>:<Uttryck FALSKT>;
a = (b > 5)?b:0; // Om b>5 blir a=b, annars blir a=0.
cBokstav = (cSvar = ‘j’)?‘A’:cBokstav;
// Om cSvar är ‘j’ ska cBokstav vara ‘A’, annars oförändrad
//sizeof
int iVar = 532;
int iLangd;
iLangd = sizeof(iVar); // iLangd = 2 (bytes).
iLangd =
sizeof(char); // iLangd = 1.
iLangd = sizeof(sVara); // iLangd = 27 (se sVara ovan!).
//Styroperatorn
long lVar;
iVar = lVar; // Kompilatorn klagar: Fel typ! (Kan inte // konvertera...).
iVar = (int)lVar; // OK, men du ansvarar för resultatet!
Klassrelaterade operatorer:
Vi kommer att titta mer ingående på klasser senare, men lägg märke till att operatorer kan användas på klasser och objekt. De kan även omdefinieras, se: ‘Överlagrade operatorer’.
Vad som speciellt är att märka är att en operator inte alltid är vad den ser ut att vara när det gäller klasser och objekt. Om vi t.ex. använder klassen ‘CString’ för att hantera en text, och initierar texten m.h.a. ‘=‘:
CString csSkola = ”Datortek Kompetensutvecklarna i Malmö”;
...så kommer det inte att fungera som ett vanligt tilldelningstecken. Ett sådant kan ju inte användas till att tilldela en lista ett värde.
I stället kommer en funktion i klassen CString att aktiveras, och den utför någon motsvarighet till strcpy().
Programstrukturen
Att programinstruktionerna måste stå i ordning för att programmet ska fungera rätt är inte så svårt att förstå, men var kommer de övriga delarna in? Låt oss titta på strukturen hos ett enkelt program (vi kommer att titta närmare på de olika komponenterna senare):
#include <stdio.h>
#define PI 3.14F
float RadieTillArea(iRad)
int iRad;
{
float fArea;
fArea = iRad * iRad * PI;
return fArea;
}
void Utskrift(A, R)
float A;
int R;
{
printf("En cirkel med radien %d har ytan %f",R,A);
}
void main()
{
float fArea;
int iRadie = 3;
fArea =
RadieTillArea(iRadie);
Utskrift(fArea, iRadie);
}
Låt oss konstatera att:
· Först står alla #include och #define (vanligtvis).
· Sedan kommer all kod.
· Koden är indelad i funktioner.
· Funktionerna har sin struktur (deklarationer
före programsatser).
· En funktion får inte anropa en annan
funktion om inte kompilatorn redan har
läst den andra funktionen (eller en förhands-
beskrivning av den, vilket vi kommer till senare).
· Det får alltså inte förekomma kod som är
beroende av något som inte står tidigare.
· Det är viktigt att tänka på var variablerna deklareras.
· Variabler som deklareras mellan ‘{‘ och ‘}’ i en funktion
är bara kända i den funktionen (lokala).
· Variabler som deklareras mellan funktionsheadern
och ‘{‘ tar emot data som skickats till funktionen, men
är kända inom funktionen under angivet namn.
· Variabler som deklarerats före första funktionen är
kända i hela programmet (globala).
Allt detta kommer att beröras i kommande kapitel. Det är inte meningan att du ska ‘förstå’ allt på en gång. Använd detta kapitel som referens genom hela kursen, så kommer du att se bitarna falla på plats efter hand.
Innan vi tittar på hur man hanterar texter i ett språk som egentligen inte stöder text, tar vi och mjukar upp med ett par övningsuppgifter:
Övningsuppgift:
·
Skapa ett projekt cirkel.
·
Skriv in källkoden från föregående sida och spara som c:\CCpp\cirkel\cirkel.c.
·
Infoga källkoden i projektet.
·
Ändra ”Debug” till ”Release”.
·
Kompilera, länka och testa.
Övningsuppgift:
· Skapa ett projekt dekl.
· Skapa en ny fil och skriv in en includesats för stdio.h, samt funktionen main() med klamrar. Vi ska strax fylla i deklarationer och programsatser.
· Spara filen som c:\CCpp\dekl\dekl.c.
· Lägg till filen i projektet.
· Deklarera en heltalsvariabel (int) som heter iSize.
· Deklarera en teckenvariabel (char) som heter cVariabel.
· Tilldela cVariabel värdet ‘A’.
· Tilldela iSize resultatet av programinstruktionen ‘sizeof’ med cVariabel som argument (d.v.s. inom parantesen, se sid 13).
· Skriv nedanstående utskriftssatser, vilka redovisar resultatet:
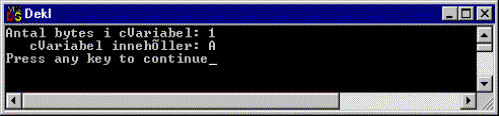
printf("Antal bytes i cVariabel: %d\n", iSize);
printf(" cVariabel innehåller: %c\n",
cVariabel);
· Kompilera, länka och testa. Så här ska resultatet bli:
Här upptäcker vi tyvärr att kompilatorn inte översätter Windows ANSI-koder till Dos ASCII dito. Vi får antingen hålla oss till engelska, eller acceptera felaktiga svenska tecken.
En annan uppenbar lösning är att arbeta i den miljö programmet är avsett för, d.v.s. starta ‘MS-Dos prompt’ och redigera programmet m.h.a. ‘edit’. När du sedan redigerar programmet i Developer Studio igen blir de svenska tecknen bara fyllda block, men det fungerar att kompilera och köra.
Övningsuppgift:
· Öppna projektet dekl igen om det inte redan är öppet, och filen dekl.c.
· Starta MS-Dos prompt och byt till enhet C: och katalog C:\CCpp\dekl\.
· Skriv: ‘edit dekl.c’, och rätta bokstaven ‘å’. Stäng edit.
· Växla till Developer Studio och observera att ändringen uppmärksammats.
· Kompilera, länka och testa.
Överkursuppgift:
· Öppna projektet C:\CCpp\dekl om det inte redan är öppet.
· Gör tillägg för att testa längden på övriga sorters variabler.
·
Titta i förväg i kapitel 3. Där står i avsnittet ‘formateringssträngar’
hur man gör för att skriva ut variabler av olika typer.
Det kan vara intressant att studera övningsexemplet från kapitel 1:
Kompileringsdirektiv: ta med denna fil.
#include <stdio.h> <> eller
""?
<>: anger att kompilatorn ska söka i de kataloger
som angivits som standard. (Normalt de headerfiler som medföljer kompilatorn.)
"": Här kan du ange valfri sökväg och filnamn. (Detta gör du med dina
egna headerfiler.)
stdio.h innehåller standard in och utmatningsfunktioner, vi behöver ‘puts()’.
Funktionsheader:
void main() void = ger inget returvärde. Main är alltid huvudprogrammet. En funktionsheader är inte en programsats och ska därför inte avslutas med semikolon.
Funktionens kropp:
{ Början av programkroppens kodavsnitt.
puts("Hello World!"); Programsats innehållande ett
funktionsanrop och avslutad med ett semikolon.
puts() = Put string, är en funktion som finns definierad i filen stdio.h.
Du kan sätta markören på ordet ‘puts’ i din källkod och trycka på F1, så finner
du motsvarande hjälpavsnitt.
TIPS! Du kan också öppna filen stdio.h
och bläddra bland funktionsprototyperna sist i filen, och använda F1 för att ta
reda på vad de olika funktionerna gör.
} Slutet av programkroppen.
Hittills har vi sett att man kan deklarera sina variabler på två logiskt sett olika ställen. I en funktion eller utanför funktionerna. Deklarerar man den i en funktion sägs den ha lokal räckvidd inom funktionen, den kan inte användas i andra funktioner. Deklarerar man den utanför funktionerna sägs den vara global, och känd i hela filsammanhanget, d.v.s. de filer som ingår i en kompilering.
Räckvidd heter på engelska ‘scope’. Lokal räckvidd heter ‘local scope’. Global räckvidd heter ‘global scope’ eller ‘file scope’. När vi talar om ett filsammanhang, ett ‘file scope’ menar vi de filer som ingår i en kompilering, d.v.s. när kompilatorn utgår från en fil och tar med andra filer endast p.g.a. att de står med genom #include-satser.
Har man ett projekt som innehåller många källkoder (man har flera filer i fliken ‘Project files’), är det inte ett filsammanhang. Det är lika många filsammanhang som listan innehåller filer. Developer Studio startar en separat kompilering för varje fil i listan. Variabler som deklarerats i ett filsammanhang är okända i ett annat, oavsett om de är globala eller lokala.
Variabler och funktioner som är deklarerade i andra filsammanhang kan man ‘lova’ komilatorn att de kommer att existera vid länkningen. I så fall använder man nyckelordet ‘extern’. Skulle man ha lovat för mycket får man felmeddelande vid länkningen i stället.
Begreppet räckvidd/scope kommer att utvecklas vidare senare, speciellt i C++ har det mycket större mening. Se avsnittet ‘Räckviddsoperatorn’ i kapitel 8.
Enumerations - logiska namn för numeriska serier.
Man kan låta numeriska värden representeras av logiska namn i våra program. Internt lagras endast siffror, kompilatorn gör översättningen. Vill vi t.ex. använda skrivna räknetal kan vi deklarera ett antal värden:
enum siffror {ett = 1, tvaa = 2, tre = 3};
Nu har vi en ny egendefinierad datatyp 'siffror'. Den kan vi använda som vanligt för att deklarera variabler:
siffror tal;
Här har vi deklarerat variabeln 'tal', vilken kan tilldetas värden 'ett', 'tvaa' eller 'tre':
tal = tre;
if(tal > tvaa)
{
tal = ett;
}
Man behöver inte ange värden. Kompilatorn lägger automatiskt till 1 för varje nytt logiskt namn i listan:
enum bilmaerke { saab = 1, volvo, toyota, ford};
Här låter kompilatorn 'volvo' representera värdet 2, 'toyota' värdet 3 och 'ford' värdet 4.
Om man inte anger ett startvärde som ovan, startar kompilatorn från 0:
enum siffror { noll, ett, tvaa, tre, fyra, fem };
Här blir 'noll' = 0, 'ett' = 1 etc.
Man kan bryta serien var som helst genom att ange ett nytt startvärde:
enum modell { trefyrtio = 340, trefyrtioett, trefyrtiotvå, trefemtio = 350, trefemtioett, trefemtiotvå };
En praktisk nytta är numerisk representation av månader och veckodagar. Månaderna representeras ju av siffror i datum, men vill vi i stället skriva månaderna i klartext i programmet kan vi införa följande datatyp:
enum maanad { jan = 1, feb, mar, apr, maj, jun,
jul, aug, sep, okt, nov, dec };
Många datumprogram räknar fram veckodag, och då är standard att dagarna räknas från söndag = 0:
enum vdag { son, man, tis, ons, tor, fre, lor };
vdag startdag;
...
// Börja aldrig en kurs när veckan är nästan slut!
if(startdag > ons || startdag == son)
{
justeradatum(startdag);
startdag = man;
}
Det är tillåtet att upprepa värden, d.v.s. att ge flera logiska namn samma värde:
enum vaederstraeck = {norr = -1, soeder = 1,
vaester = -1, oester = 1};
Observera att man inte kan tilldela en variabel av egendefinierad enumtyp ett numeriskt värde direkt, men att det går om man använder typomvandling (int):
enum faerger {roed, groen, blaa};
void main()
{
faerger bil, cykel;
int iFaerg;
bil = roed; // Ok, bil blir roed;
iFaerg = bil; // Ok, iFaerg blir = 0;
cykel = 2; // Fel! 'Cannot convert...'
cykel = (faerger)2; // Ok, cykel blir blaa
}
Observera att vi förlorar kontrollen av att variabeln 'cykel' får ett tillåtet värde. Om man anger ett värde utanför värdelistan, eller ett som dubblerats ('norr' och 'oester' i förra exemplet var bägge = -1) så blir resultatet odefinierat.
Om man nu deklarerar en variabel lokalt, med samma namn som en global variabel, blir det två separata variabler med samma namn, en global och en lokal. Vill man ändå att det ska vara samma variabel (d.v.s. lagras på samma fysiska plats i datorns minne) så kan man i i den lokala deklarationen använda nyckelordet ‘extern’.
En annan lagringsklass är ‘auto’. Denna har omvänd funktion, d.v.s. man isolerar en lokalt deklarerad variabel från en eventuellt globalt deklarerad variabel med samma namn. Nu tänker du: ”Men så var det ju från början!” Helt riktigt. Om man inte anger lagringsklass antas automatiskt lagringsklass ‘auto’.
Förutom ‘extern’ och ‘auto’ finns ytterligare två lagringsklasser: ‘static’ respektive ‘register’.
Varje gång en funktion anropas kommer den att deklarera sina interna variabler, varigenom de initieras på nytt. Detta innebär att en funktion inte ‘kommer ihåg’ vad den sysslade med mellan de olika anropen. Alla lokalt deklarerade variabler är av temporär art. De kan dock göras statiska, d.v.s. att de behåller sina värden mellan anropen, genom att man använder nyckelordet ‘static’ vid deklarationen. Därigenom deklareras (och initieras) en variabel bara första gången funktionen anropas.
Den sista lagringsklassen är ‘register’. Den betyder att man vill att datorn lagrar data direkt i något av processorns register, några mycket mycket få och mycket upptagna ‘minnen’ inuti processorn. Om data lagras där sker bearbetning mycket snabbare än annars. Det är dock inte säkert att det finns ledigt registerutrymme.
Linkage Specifications, länkspecifikationer.
Om vi har ett C++ projekt och vill använda funktioner som redan kompilerats i C måste vi förklara detta för länkaren. Det kan finnas flera situationer där detta blir aktuellt.
Anta att man av någon anledning vill skriva en funktion i C i stället för C++. Då skapar man en separat fil för den funktionen, sparar filen med filnamnstillägg '.c' och anger att den ska vara med i projektet (Project - Edit... <projekt>.mak).
I den C++ fil där anrop till C-funktionen sker måste man som vanligt lägga till en prototyp (eftersom funktionens gränssnitt inte är känt, se ‘prototyper’ i kapitel 8). Skillnaden är att man anger att den kompilerats som C-program. (När man kör sin 'Build' väljs kompilatorns arbetssätt enligt filnamnstillägg. Varje filsammanhang aktiverar kompilatorn för C eller C++ kompilering.)
extern "C" void funk_a(char*, int);
Vill man ange flera funktioner som C-funktioner kan man använda klamrar:
extern "C"
{
void funk_a(char*, int);
void funk_b(char*);
void funk_c(int);
}
Om man har kompilerat filerna tidigare, och tagit med objektkoden i stället för källkoden i projektet, så kan man t.ex. ha en headerfil med funktionsprototyper:
extern
"C"
{
#include
"myhead.h"
}
Med kompilatorn förljer ju ett stort antal färdigkompilerade C-funktioner, vilka vi kan använda i C++. Ett C++ projekt innehåller därför en speciell deklaration som headerfilerna kan testa på när man kompilerar (villkorlig kompilering):
I början av filen:
#ifdef
__cplusplus
extern
"C" { /* Assume C
declarations for C++ */
#endif /* __cplusplus */
...
...
Och i slutet:
#ifdef
__cplusplus
}
#endif /* __cplusplus */
Vilket gör att allt i filen deklareras som 'extern "C"' när man kompilerar ett C++ projekt.